Bridged Indexes in OrioleDB: architecture, internals & everyday use?

Since version beta10 OrioleDB supports building indexes other than B-tree. Bridged indexes are meant to support these indexes on OrioleDB tables.
1. Why OrioleDB needs a “bridge”
OrioleDB stores its table rows inside a B-tree built on a table primary key and keeps MVCC information in an undo log, so it can’t simply plug PostgreSQL’s existing Index Access Methods (GiST, GIN, SP-GiST, BRIN, …) into that structure. While PostgreSQL's Index Access Methods:
- reference a 6-byte
ctid(block number and offset in the heap) -- not a logical key; - keep every live version of a row in the index, leaving visibility checks to the executor;
- support inserts only in the index and rely on
VACUUMfor physical deletion.
OrioleDB indexes, in contrast, are MVCC-aware: they point to the rows via primary-key values and support logical updates/deletes directly in the index. To remain heap-free while still allowing users build the rich ecosystem of non-B-tree indexes, OrioleDB introduces a bridge index layer.
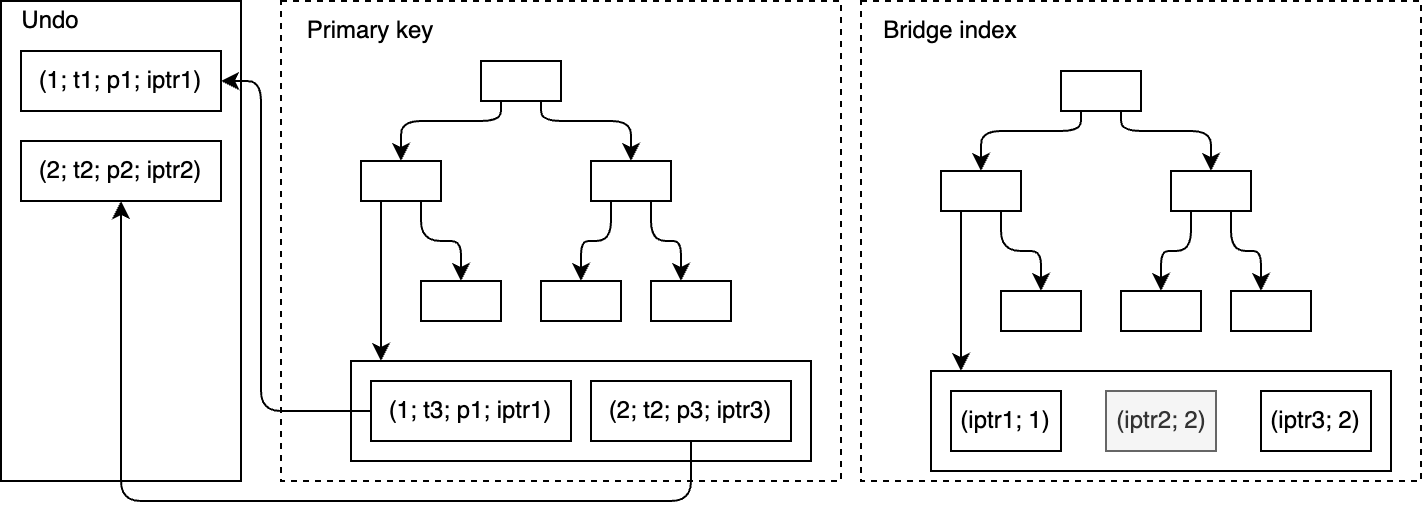
2. How the bridge works under the hood
- Virtual
iptrcolumn -- an incrementally increasing "index pointer" automatically added to the table. The new value of iptr is assigned each time any column referenced by a bridged index is updated, ensuring the pointer remains stable for the indexed data. - Bridge index -- a lightweight secondary index that maps
iptrto primary-key value. It behaves like a normal OrioleDB secondary B-tree, except it has limited usage of the undo log for MVCC handling: deleted versions aren't automatically wiped off. - PostgreSQL indexes (GIN/GiST/...) are built on the
iptrvalues instead of ctids, so their structure stays compatible with the IndexAM API. During scans, the engine looks up iptr, translates it through the bridge index, and then fetches the row by primary key. - The vacuum process collects stale
iptr-s that are not visible to any snapshot, and asks the underlying IndexAM to clean up; then physically deletes the same pointers from the bridge index.
The result is a tri-level lookup path: IndexAM index → iptr → bridge index → primary-key fetch, giving full AM compatibility at the cost of one extra index hop.
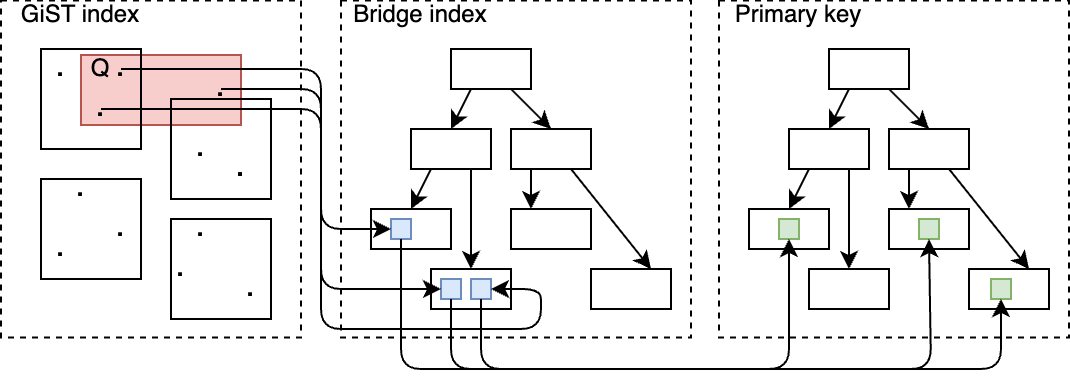
3. Everyday usage
3.1 Automatic bridging (the "it just works" path)
The first time you create a non-B-tree index on an OrioleDB table, the extension implicitly adds the bridge:
-- Title column full-text search
CREATE INDEX blog_post_title_gin_idx
ON blog_post USING GIN (title);
Behind the scenes OrioleDB:
- Adds the hidden column
iptrto theblog_posttable, - Builds a bridge index mapping
iptrto primary key, - Builds the user-requested
blog_post_title_gin_idxon theiptrs.
So, for most applications you don’t have to do anything special.
3.2 Manual control (when you need it)
You may prepare the bridge layer on the table in advance to save time during adding an index. Also, you can remove the bridge layer if it’s not needed anymore.
-- Force creation (useful before bulk loading data)
ALTER TABLE blog_post SET (index_bridging);
-- Drop all non-B-tree indexes and then remove the bridge
ALTER TABLE blog_post RESET (index_bridging);
You can even ask OrioleDB not to use the native B-tree implementation for testing purposes:
-- Builds a *bridged* B-tree (slower – do this only for experiments)
CREATE INDEX blog_post_title_idx
ON blog_post USING btree(title)
WITH (orioledb_index = off);
Commands and options are documented in the Getting Started guide.
4. Performance notes
- Expect an extra hop. A bridged plan adds roughly one more B-tree lookup per matched row. For complex AMs (e.g. pg_vector ANN search) the overhead is usually negligible; for indexes with cheaper lookups (e.g. GiST or GIN) you are expected to see some overhead.
- Updates pay twice. Similar to the heap tables, changing a column that participates in a bridged index bumps the
iptr, which means inserting a new entry into every bridged IndexAM and into the bridge index. The good thing is that changing a column that participates in only OrioleDB built-in B-tree indexes, no overhead is expected.
5. Conclusion
OrioleDB’s bridged indexes give you the best of both worlds:
- Modern, MVCC-aware, index-organized storage for the table itself;
- Full access to Postgres’ rich IndexAM ecosystem — GIN for full-text, GiST for spatial, pgvector’s HNSW, RUM, BRIN and more — without rewriting those extensions.
While a third-party index rewritten to be a native OrioleDB index will always be faster, the bridge means you no longer have to choose between raw speed and the extension you love. Try it out in your dev database, measure the overhead on your workload and keep an eye on the fast-moving roadmap — 2025 is shaping up to be a big year for OrioleDB.